
Untangling sources of truth with an event-driven system

A public sector client had a problem that will sound familiar to a lot of teams—multiple systems all claimed to be the source of truth for the same citizen data. An identity provider handled SSO, a CRM platform, and various internal APIs and verification providers also joined the mix.
But users don’t care if one backend has their email address and another has their PO box. They care about a seamless experience as they move across different applications, with consistent and accurate data at every step.
To solve this problem, we built an event‑driven architecture on cloud messaging and queue services. It helps maintain consistency and recovers gracefully when third-party APIs are degraded or unavailable.
This article recaps how the architecture grew from a simple “seed” to a full “forest,” based on a recent lightning talk I gave at the Code for America Summit in Chicago.
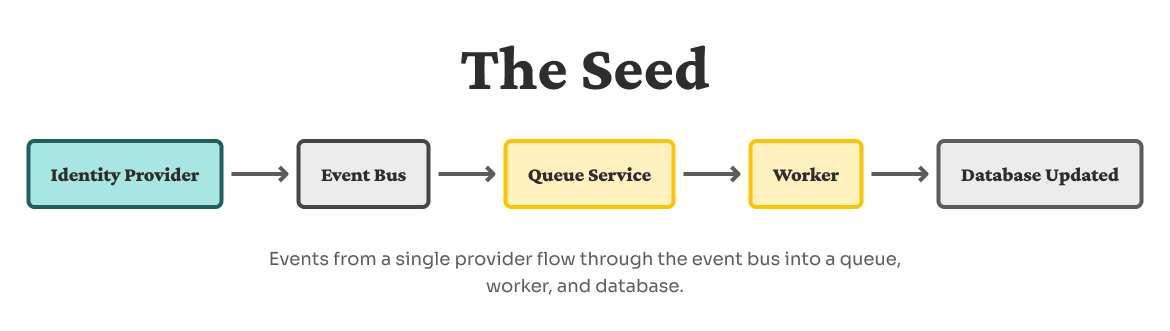
The seed: A simple event pipeline
We started with an intentionally simple pattern:
- An event comes from a third party.
- The event bus routes it to a queue.
- A worker processes that queue.
- The database is updated if needed.
This “seed” architecture already decouples the external identity provider from our application database, and gives us a place to absorb spikes in incoming events.
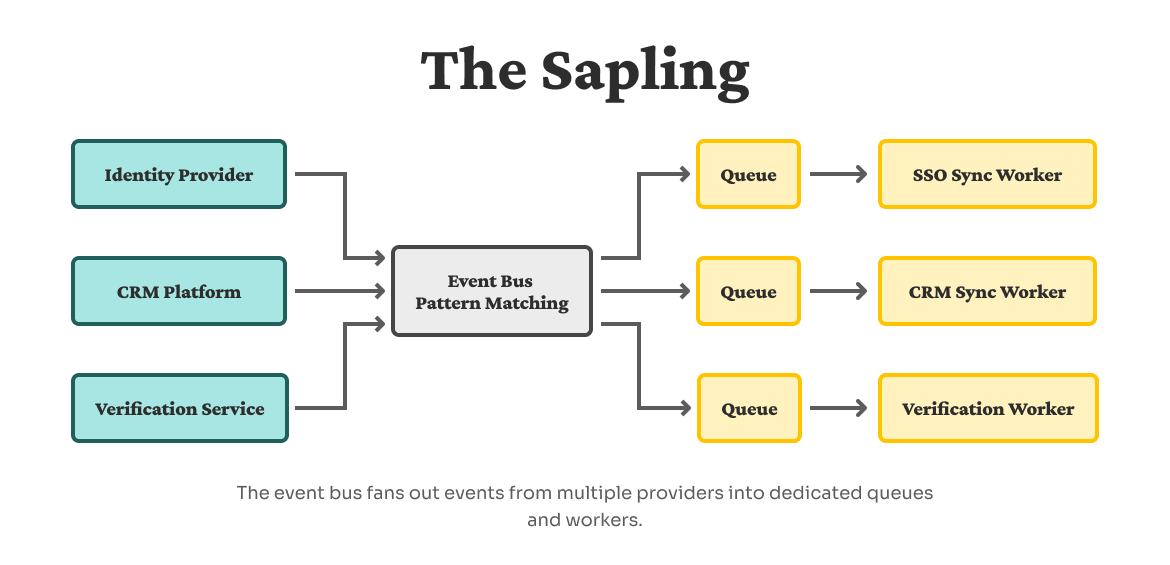
The sapling: The event bus as the pattern-matching trunk
As we added more providers, we needed to handle new event types—like identity verification webhooks and change data capture (CDC) events—but without constantly changing our application code.
The event bus became the “trunk” of our sapling. It doesn’t care whether something is a login, profile update, or a verification event. It simply matches patterns and routes events to the right queues. Dedicated workers consume from those queues, each focused on a specific concern like SSO sync or CRM sync.
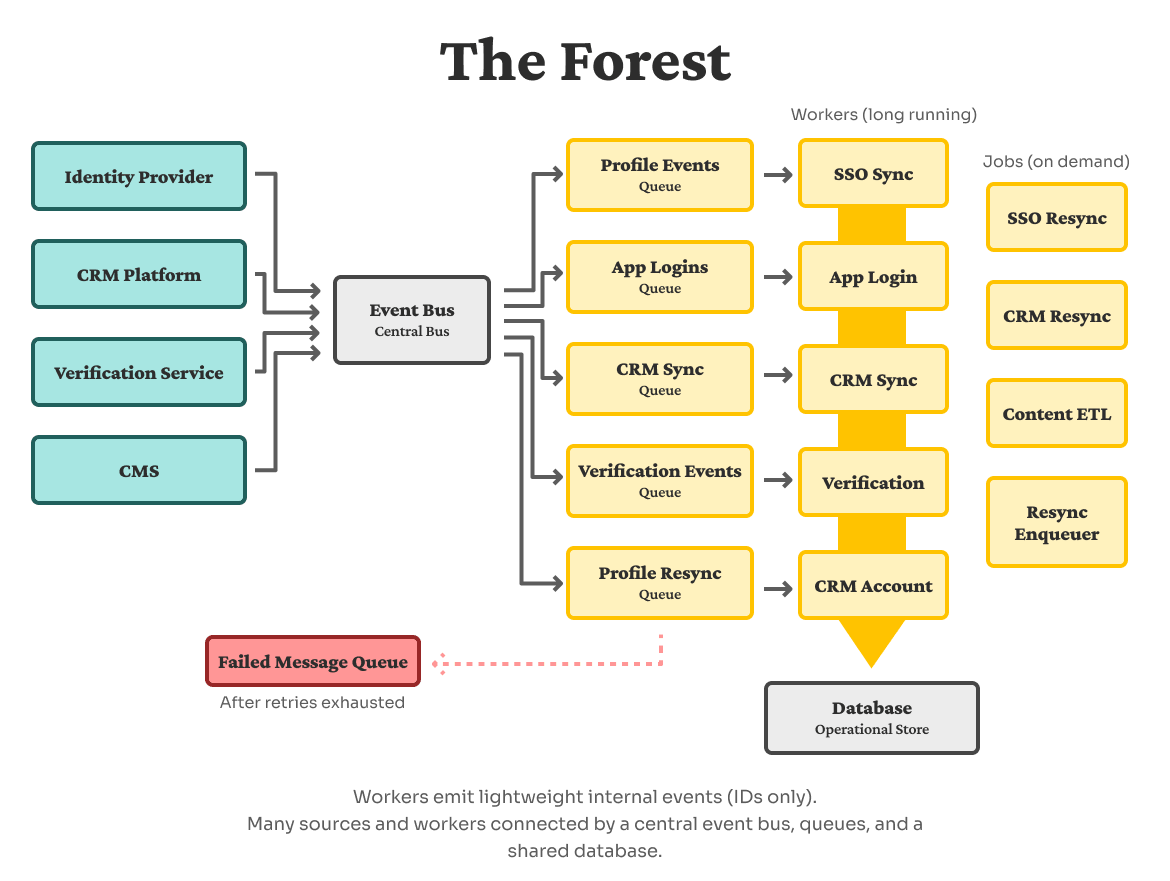
The forest: A living ecosystem of events
Once we had the routing and the queue system in place, we were able to progress to a full, living and breathing event ecosystem—what I called the “forest.”
Multiple systems now emit events into the central bus, which fans them out into specialized queues—profile events, app logins, CRM account updates, identity verification events, resync queues, and more.
We have two kinds of consumers handling these queues:
- Long-running workers (SSO sync, app login, CRM sync, identity verification , CRM account) that handle queue processing continuously.
- On-demand jobs (SSO resync, CRM resync, content ETL, a resync enqueuer) that wake up to handle specific scenarios like resyncing from a third‑party API.
All of this flows into our operational database, while workers also emit internal events back into the event bus so other parts of the system can react without being tightly coupled to any single source. When a third‑party provider experiences disruption or a worker encounters errors, queues and the central bus give the system room to absorb the noise and recover gracefully.
What keeps our event-driven ecosystem alive
There are three principles that keep this kind of event-driven system healthy.
1. Repeat‑safe processing
In this architecture, retries and reprocessing are normal. If you run the same message or event multiple times, you want to end up in the same correct state every time.
Designing steps to be “repeat‑safe” means that any reprocessing—whether from automatic retries or manual intervention—does not corrupt data or create surprises for users.
2. Internal events carry IDs, not data
One key thing we learned is that internal events should usually carry minimal identifiers (with a few exceptions). Otherwise, the data can go stale by the time it’s handled, leaving you with bad race conditions that are hard to solve.
Instead, internal events carry IDs that point back to the authoritative source for a given domain—whether that’s our operational database, CRM platform, or another system—so that when a worker processes an event, it pulls fresh data at that moment. That way, re‑drives always pull the truth rather than replaying an old snapshot.
3. Automated recovery mechanisms with observability
Fault-tolerant event handling is a first‑class part of this ecosystem, not an afterthought. After a limited number of retries, failed messages are routed to isolated holding areas where they can be inspected, understood, and reprocessed.
Those holding areas are wired up with automated alerts so engineers are notified when something starts to fail, rather than discovering it weeks later. Failure is normal in a system like this, but silence is dangerous. If fault-tolerant queues stay empty for long periods, it’s important to verify your retry logic, alerting, and failure instrumentation are actually working.
Final thoughts on our event‑driven architecture
Our event‑driven approach turned a tangle of competing sources of truth into a system where multiple applications can share consistent data without being tightly coupled to one another. The central event bus handles pattern matching and routing, queues smooth out spikes and isolate failures, and workers and jobs can evolve independently as the ecosystem grows.
By keeping internal events lightweight and ID‑based, and fault-tolerant event handling as core design principles, the system can keep breathing even under real‑world failure modes.
If you’re wrestling with competing sources of truth across your own systems, this kind of event‑driven “forest” might be a solution worth exploring. Get in touch with us to find out more, or learn about our expertise.
This article was created in partnership with our content writer, Peggy McGregor.



